{kind=link}
By Rob Orton
With our years of experience with customers around the world and across sectors, our Scality solution engineers know how to maximize data protection and availability for IT. We’ve seen that stretched, multi-site architectures give customers incredible uptime, but there are several key factors on your network to consider before deploying.
In other words, we want to help our customers optimize their network to make deploying Scality RING a breeze. So, how do you improve your network to ensure it’s in tip-top shape and ready for a stretched architecture? Read on.
Stretched, multi-site Scality RING deployments: Establishing RPO & RTO targets
Fast recovery, protecting data without impacting application performance or availability
For most organizations, the preferred deployment model for Scality RING is what’s called a stretched architecture — one where all the nodes of a cluster are spread evenly across different physical sites (availability zones in cloud parlance). Two or three-site stretched architectures are common for Scality. This approach to data protection ensures that an entire site — plus another server or disk group — can fail, while still maintaining full read-write access with zero recovery point objective (RPO) and recovery time objective (RTO.)
Why is this important? It means even if a site is down or inaccessible due to a power outage or network issues (or something more serious), you still have protection against another failure without impacting application availability.
Achieve ultimate protection with faster recovery time, while eliminating data loss
To protect and secure data over multiple locations, RING is configured as a fully synchronous stretched cluster — guaranteeing data is only acknowledged back to the application once it is fully committed to persistent media.
This type of data layout over multiple sites, coupled with Scality’s data protection capabilities, helps customers achieve 14 nines of data durability. It’s part of why the world’s most discerning and data-informed organizations entrust their mission-critical data to Scality.
Simplify operations in the event of a failure with synchronous stretched architectures
Another way to protect data over multiple sites is with asynchronous replication. This is when two independent RINGs replicate all (or a subset) of the data to each other. It’s used when there is a greater distance or slower performing network between sites than a stretched RING can support.
Although this approach has benefits allowing longer distances between data centers, organizations generally prefer the synchronous data protection of a stretched RING as it simplifies operations in the event of a failure. In addition to potentially elongated and complicated RTO, asynchronous replication always carries an RPO, meaning that some of the most recent data will not be protected on the second site. This might not be the best fit for the data protection needs of some organizations or applications. Depending on factors such as the data change rate of the application and the bandwidth or latency of the network linking the sites, the RPO can become too great to tolerate.
Async & Sync
Asynchronous Replication between RINGs
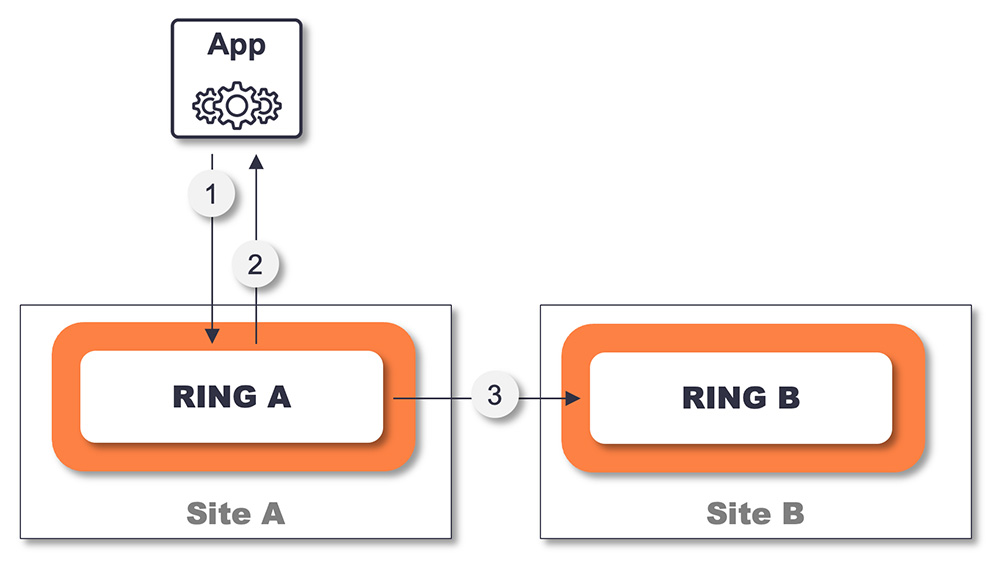
- Data is written to RING and protected across all servers
- Data is acknowledged back to the app once it is committed to persistent media on all servers
- Data is asynchronously replicated to the target RING
Synchronous operations in a stretched RING
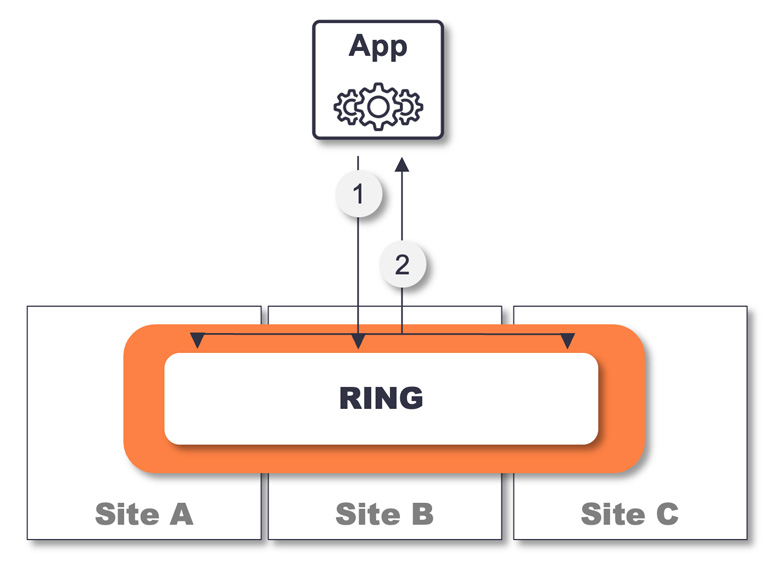
- Data is written to RING and protected across all sites
- Data is acknowledged back to the app once it is committed to persistent media on all servers on all sites
Asynchronous replication vs. synchronous operation
The bottom line is that a synchronous stretched architecture with clear RPO and RTO targets can greatly improve the business impact. The business can work with IT to establish these targets because they typically tie strongly into service-level agreements (SLAs) between the application and its users, whether they are internal or external customers.
More stretched RING benefits: Bolstered protection and increased efficiency
A stretched RING can have other benefits outside of RPO and RTO. For example, many customers use Scality as a backup target. By sending data to a stretched RING, the backup is, in effect, immediately protected from a site loss, so it can mean the backup doesn’t need to be further copied to a different location.
Another benefit of a stretched RING is that it is an efficient way to store and protect data, which matters at scale. Some of our customers have video recording data that ranges into the scale of tens of petabytes, which is impossible to reproduce. This valuable data must be protected, but the hardware required can be prohibitively expensive. Scality RING minimizes this cost.
Cost savings: 3-site stretched vs. 2-site replicated dramatically saves hardware overhead
It’s typically about a 75% overhead to protect large data on a three-site stretched RING. In comparison, if this data was replicated between two RINGs, there would be a 100% overhead for the extra copy of data, then another 33% overhead per site for the local protection.
In this case, by overhead, we mean the amount of extra storage hardware that needs to be provisioned in order to guarantee that data is protected in the event of dual failure, including a site loss.
Pro tip: Identify and resolve any existing network issues before deploying a stretched RING
In approximately one-third of stretched architecture implementations, we find there are some network issues that need to be addressed before rolling out RING.. These issues — ranging from a few minor misconfigurations to out-of-date hardware — already exist in the customer’s network and are uncovered as we begin RING implementation.
To avoid delays and ensure you achieve full and immediate value from RING, it’s important to prepare your network. For optimal deployment, what we’re typically looking for is 10Gb/s or greater bandwidth and <5ms latency on the wide area network, though this can vary depending on the workload and performance expectations of the customer.
As mentioned above, problems can arise in many areas of the network. Here are the most common issues to look out for and address:
- Fix packet loss: Packet loss is when a network packet fails to reach its expected destination, usually to protect the network from being flooded or to maximize efficiency, and it can happen due to a number of factors. Traffic shaping, such as rate limiting or connection limiting, can inadvertently interfere with RING traffic. When packets are dropped, the sender will retry after a timeout period — this can increase latency and the re-sent packet consumes additional bandwidth, further reducing the total bandwidth available for other applications or network traffic.
- Optimize routing: The route the packets take across the network is important for a distributed storage cluster like RING. As per all network traffic, we need to ensure it takes the fastest route over the most suitable links. We have seen a case in the United Kingdom where packets for a data center 20 kilometers away were being sent over 300 kilometers to the north of England and 300 kilometers back to the south coast. That extended distance incurred a greater latency than the application could sustain, which resulted in an incredibly slow response. The takeaway: Make sure to architect the network design so the data can follow the fastest route!
- Avoid link saturation: Try these recommendations to avoid link saturation, which can manifest itself in a number of ways:
- Correct underlying routing issues: As mentioned above, networks misrouting traffic over links that don’t provide enough bandwidth can quickly saturate the path and affect RING performance. This can be easily remedied by correcting the underlying routing issues.
- Evaluate peak times and determine the right bandwidth: Physical links are often shared with other applications, which can lead to unexpected behavior on RING. Sometimes peak utilization is not accounted for when assessing the available capacity of the ISL with links saturating at certain times of day, or when specific processes run. A correctly designed quality-of-service (QoS) policy can help mitigate these situations, or permanently provisioning more bandwidth will remedy the problem. As part of a RING implementation, extra bandwidth is sometimes needed and promised by the business. However, we have seen delays in this being implemented, which can then delay the full roll-out of RING.
- Consider every link in the chain: We have even seen customers experience slow response to the end user when the connections to the desktop were only 1Gb/s, and they were unable to ever realize the expected performance until they were upgraded.
- Review intrusion detection systems (IDS) rules: A stretched RING is a distributed storage cluster, so it uses a lot of connections. Each object or file an application reads or writes consists of at least 12 chunks of data on the backend. Clearly, the amount of required connections between all RING resources can be significant. The 12 chunks are essential to deliver up to 14 nines of data durability, but from the view of an IDS, all of these connections can start to look like an attack on the network — which can trigger the IDS to restrict some traffic. You have to set up IDS rules correctly to allow RING components to access their required connections.
- Look out for cable seating issues: Ah, yes, the nemesis of a network admin. Some of our customers with higher performance demands have very fast and rock solid networks. Recently, however, we had one customer who started to suffer performance degradation on one of their links. Nothing had changed in that area of the network and it had run well for a long period of time, so that router (including the cable/port) was not the source of any initial investigation. A few errors appeared on the link but the fault was intermittent and the issue was not identified and pinpointed right away — a typical ‘flappy link.’ Eventually, over time, as the cable eases its way out of the port, the problem fully reveals itself where it can be identified and easily rectified.
- Make sure to use a health-checking load balancer: For S3 RING implementations, an external load balancer is required. This ensures the full performance of RING can be unlocked by distributing traffic over multiple endpoints and allowing scalable, parallel data access. We always recommend using a load balancer that has health-checking functionality. Why? If an endpoint is down for some reason — without health checking, data will still get sent to that faulty endpoint. The application will wait for a response until the timeout period passes, whereas it will retry and, hopefully, hit a working endpoint. This will continue to happen and will reduce frontend application performance until it is removed. Hardware-based load balancers can also have throughput limitations; these should be accounted for when scoping.
Best practices for putting a stretched architecture in place
The Scality pre-sales team will typically work closely with your organization’s IT team to understand what you need from Scality RING. Based on your application and performance requirements, they’ll make recommendations regarding network requirements. In some situations, use of RING can uncover long-term hidden faults in the network that you weren’t aware of, such as routing errors or outdated hardware (as mentioned above.)
It’s best to involve the network team at an early stage. Doing so ensures they fully understand the extra workload RING will place on the network, especially in terms of bandwidth. It also allows time for any possible redesign, reconfiguration or investment in new equipment or links needed. We find that the best implementation projects occur when all the IT stakeholders, including the customer’s network team, are involved and communicate regularly.
Other recommended best practices:
- Implement network quality of service policies that can prioritize RING traffic, or use dedicated VLANS with defined bandwidth that can segregate and provide a suitable level of performance to RING traffic.
- Update software/firmware on network devices, which will provide more stability and improve performance. Double-check to ensure these are configured properly.
- Regularly monitor and analyze the network to identify and address underlying causes of latency, such as packet loss or congestion. In the words of one of our implementation engineers, “monitor, monitor, monitor; put eyes everywhere and monitor and graph every port.”
- Consider a network analysis service delivered by a third-party prior to scoping RING to get an independent view of the network and enable any issues to be uncovered and addressed.
Correcting network issues can also help organizations realize other benefits, such as freeing up network throughput or increasing resilience. Managing networks is complex and time-consuming, but it’s a must-do.
Setting your organization up for success with Scality RING
Scality RING can help organizations of all sizes achieve unparalleled scalability and security with best-in-class performance at a competitive cost. It’s the storage solution for your smart, flexible cloud data architecture. Achieving maximum benefits from deployment, however, can only be done if you’ve taken the time to put the right foundation in place. At Scality, we’re dedicated to helping our customers get the most bang for their buck by ensuring they’ve laid the groundwork for success.